

Part Two
Secure Your Software Supply Chain – Threats and Mitigations
This is part two of a two-part blog series on third-party code usage in software development. In this blog post we aim to weigh threats and mitigations that are relevant when working with third-party components.
- Insight

Following up on that, we now aim to weigh threats and mitigations that are relevant when working with third-party components. We will not go into detail on how to identify threats, but rather use a list that Truesec has prepared for this purpose.
Read part one: Secure your software supply chain – trusting third parties.
Threat Categories for Third-Party Dependencies
We have concluded in the previous part that the threats we will examine could lead to full compromise of the systems involved. Unless we want to conclude that the mitigation is to “not use vulnerable or malicious dependencies”, we need to look a bit deeper at the different processes that can lead to a vulnerable or malicious dependency being used. To do this we will categorize the threats into six basic threat categories:
- An attacker uses a known vulnerability in a dependency.
- An attacker uses a semi-known vulnerability in a dependency.
- An attacker uses a known vulnerability class.
- An attacker uses an unknown vulnerability in a dependency (“zero-day”).
- A publisher adds malicious code to a dependency.
- An attacker leverages a publisher to exploit the system (“supply chain attack”).
Later we will also mention some additional threats and mitigations that are or will be available.
Zero-Day Semantics
If a tree falls in a forest and no one is around to hear it, does it make a sound? If software is vulnerable and no one is around to exploit it, is it really a risk?
Ancient Infosec Thought Experiment
For this blog post, we chose to never call a published vulnerability a “zero-day”. Once information about a vulnerability is published it is technically possible for tooling to alert on it, even if there is no quick fix. How quickly that information is available in tooling depends on the quality of the vulnerability feed in use. So, in this context, a zero-day represents the terrible unknowns where the attacker has an upper hand by knowing about a vulnerability before the consumers reasonably can (although, the publisher might already be aware).

Let us have a look at the definition of these categories.
Threat 1: An Attacker Uses a Known Vulnerability in a Dependency
This is the simplest threat to reason about. Here a vulnerability is publicly known and likely available in vulnerability feeds. As developers, we can know about the vulnerability if we follow available sources. Hopefully, there is a patch or mitigation available as well.
Threat 2: An Attacker Uses a Semi-Known Vulnerability in a Dependency
We chose to separate “known” and “semi-known” vulnerabilities here. This is not an industry standard, but it can be useful to separate these categories. A semi-known vulnerability is in this case a vulnerability where the bug has been acknowledged or at least publicly mentioned, but it has not broadly been classified as a known security vulnerability (perhaps lacking a CVE). This can be true in a variety of cases:
Patching Without Security Notice
The publisher has patched the vulnerability but has not yet disclosed it as such.
Perhaps to make sure users patch before exploitation, but more likely since the publisher does not want to request a CVE or does not want to acknowledge the security consequences of the bug.
It could also be that the publisher patches a vulnerability but labels it only as a bug due to not realizing the security consequences of the bug.
Incomplete Patches
The publisher has incorrectly patched the vulnerability, making exploitation easy (and in doing so instead highlighted the issue).
This can happen if the publisher just mitigates a very specific exploit method without realizing that very similar but slightly adapted exploits are simple to produce. For example, if the vendor introduces a filter or regular expression for certain behavior without solving the actual underlying issues. An example of this is solving a deserialization remote code execution (RCE) by trying to filter a set of specific dangerous gadgets. This is close to a 0day, but these are cases where it is obvious to relevant observers that the issue remains. That fact would have been hidden were it not due to the initial publication of the first vulnerability.
Release Without “Responsible Disclosure”
A vulnerability is publicly disclosed without vendor action or CVE assignment. For example, through a GitHub issue or a tweet.
This happens for example when:
- The reporter does not realize the security implications of the bug
- The publisher does not provide channels to report security issues
- The reporter feels like doing an immediate full disclosure without first allowing the vendor to fix the issue.
Threat 3: An Attacker Uses a Known Vulnerability Class
This class borders both zero-days and security misconfiguration. Historically, types of vulnerabilities have become sudden massive targets of exploitation. Often due to articles highlighting a newly discovered vulnerability class or a vulnerability class that has flown a bit under the radar. Typical examples of this are XML External entity attacks and Object deserialization attacks. More recently Server-Side request forgery (SSRF) and its potential effects have been very visible in for example OAuth2 based flows and modern microservice solutions. Incorrect use of authentication tokens such as JWT through insecure defaults in libraries can also be said to fall in the same category.
Threat 4: An Attacker Uses an Unknown Vulnerability in a Dependency (“Zero-Day”)
This one is probably the scariest threat, but luckily not the most likely. These are vulnerabilities where the threat actor finds and exploits an unknown vulnerability in a third-party component you use. In doing so, the attacker risks leaking the exploit method by using it, which ideally would lead to the publisher patching the vulnerability, thus making the exploit less valuable. If your threat model assumes the threat actor to have access to and willingness to use valuable 0days in dependencies, you will probably need to take even more measures than will fit in this blog post.
Threat 5: A Publisher Adds Malicious Code to a Dependency
This one could seem even more unlikely, but in fact, is not. While it is unlikely that a maintainer of an open-source library would suddenly turn evil, popular projects will often get requests to add seemingly innocuous code to the project. Even more likely, the maintainer could lose interest in maintaining the component and some other person or organization steps up and takes over the package identity with bad intentions in mind.
Threat 6: An Attacker Leverages a Publisher to Exploit the System (“Supply Chain Attack”)
This class is also one of the scarier ones. In this case, the publisher of the component has good intentions but is either breached or inadvertently uses some other dependency that is malicious. Even if we generally trust the publisher, it could be that the publisher has malware added to the package being published. The attacker can in this case leverage a supplier that publishes a popular component (or just a component used by an interesting target). This can provide the attacker with access to many systems at once as well as simplify attacking systems that are otherwise difficult to breach.
Potential Mitigations
To comfortably use third-party dependencies, we will want to look at mitigations to the abovementioned threats. We will categorize these mitigations into eight basic mitigation categories. There are more potential mitigations, and some are mentioned later in this post. Our eight categories are:
- Software Composition Analysis (SCA)
- Alerting on known vulnerabilities
- Removing dependencies
- Automatic patching
- Automatic pull requests
- Quarantine
- Isolation
- Vendoring
You might react to SCA and alerting being two different mitigations, but there is a reason for that: Just knowing the ingredients of the software can help you react to vulnerabilities even if automation is not set up or functioning.
When we map the threats we will do so by categorizing:
🟩=”actively useful against threat”
🟨=”partly useful against threat”
🟥=”not useful against threat”
This categorization is meant to be general, and you might not agree in all cases. That’s fine. Either way we have now hopefully started a meaningful discussion about threats and are looking at the value of our security controls.
Mitigation 1: Software Composition Analysis (SCA)
This is about figuring what your software contains. Software composition analysis can be manual work, partly automated, or wholly automated. The tooling can be basic or have complex integrations and interfaces. Choose something that fits your process but be sure to do it somehow. SCA is the basis for almost all other mitigations. You cannot reasonably expect to patch what you do not know about.
In many environments, you can get a basic picture of the packages that are directly or transitively included using standard tooling such as “dotnet list –include-transitive”, “mvn dependency:tree” or looking at lockfiles for the package manager. This will however not necessarily show libraries or snippets added to the source code repository, nor dependencies used at runtime or for example in containers.
Most likely you will be looking at using tooling from vendors/trademarks like GitHub, GitLab, Snyk, WhiteSource, Black Duck, JFrog, Nexus, Synopsys, Veracode, VulnDB, or any of the many other vendors in this space (this is not an endorsement of any of previously mentioned vendors).
Usefulness against the investigated threats:
| 🟩 | Known Vulnerabilities Very useful. This is the main use case for SCA |
| 🟩 | Semi-Known Vulnerabilities We might be able to read release notes and similar to find these issues |
| 🟨 | Known Vulnerability Class Can be useful. Assuming we look at what goes into the component and can react and triage if attack classes become popular |
| 🟥 | Zero-Day Will not help us |
| 🟨 | Malicious Publisher Can help us analyze who to trust |
| 🟨 | Supply Chain Attack Can help us analyze who to trust |
Mitigation 2: Alerting on Known Vulnerabilities
If we are analyzing the components our next step is to add visibility and/or alerting when a vulnerability in something you use becomes known. This is most often one of the selling features of SCA tools. It should however be mentioned that the quality of the vulnerability feeds powering the alerting can vary. Certain commercial feeds have more information and potentially better targeting than some publicly available feeds do. Relying on NVD feeds can go a long way but will likely entail quite a bit of triage to see if you are affected (as well as missed vulnerabilities). Relying on npm audit can also go a long way but will entail the occasional missed vulnerability or delayed reporting that other tooling might find.
Usefulness Against the Investigated Threats:
| 🟩 | Known Vulnerabilities Very useful as it helps us know about the vulnerability |
| 🟩 | Semi-Known Vulnerabilities Depending on the quality of the vulnerability feed |
| 🟨 | Known Vulnerability Class Unlikely to be useful, but depends on the alerting intelligence |
| 🟥 | Zero-Day Will not generally help us |
| 🟨 | Malicious Publisher Can theoretically alert prior to exploitation. If a publisher is deemed malicious or under attack and that is known to the vendor. |
| 🟨 | Supply Chain Attack Can theoretically alert prior to exploitation. If a publisher is deemed malicious or under attack and that is known to the vendor. |
Mitigation 3: Removing Dependencies
This is the most effective method imaginable when it comes to risk stemming from a third-party component. Removing the component will naturally remove the need to patch it or triage vulnerabilities. But we did add the dependency for a reason, didn’t we?
In many applications, there are many dependencies that are not used or barely used/needed. We could be using a complex component to do some simple encoding, add libraries for functionality that already exists in the language standard library, or just bundle dependencies that are never even used. Trying to remove dependencies that are not needed or can easily be replaced by something more manageable can reduce the triage pressure and thus increase your ability to secure other dependencies.
It is likely that most of the dependencies that are included are transitive, which means that they are dependencies that are loaded by the components you depend on. Such dependencies are often hard or impossible to remove without also removing the component you depend on. In some cases, it is however possible to add an exclusion filter to not download a transitive dependency (if that transitive dependency is not loaded or used in the code paths you use).
Since we have concluded that we can most often not add dependencies without thinking, there are many cases where the cumulative cost of trust establishment, triage, and patching is higher than the business value provided by the dependency.
Usefulness Against the Investigated Threats:
| 🟩 | Known Vulnerabilities Vulnerabilities from the dependency are no longer relevant |
| 🟩 | Semi-Known Vulnerabilities Vulnerabilities from the dependency are no longer relevant |
| 🟩 | Known Vulnerability Class Vulnerabilities from the dependency are no longer relevant |
| 🟩 | Zero-Day Vulnerabilities from the dependency are no longer relevant |
| 🟩 | Malicious Publisher Vulnerabilities from the dependency are no longer relevant |
| 🟩 | Supply Chain Attack Vulnerabilities from the dependency are no longer relevant |
Mitigation 4: Automatic Patching
Now we are stepping into the exciting area of dramatic reduction in vulnerability exposure and triage while still using the component. Ideally, we would want to patch dependencies immediately in the hope of new versions being better than old versions. And while that is generally true for mature software projects, there is of course also the risk of new bugs or things breaking.
Automatic patching is not yet common in the software world, but there are very good use cases for it. If we are using continuous delivery, we can add automatic unit testing and integration testing to reduce the risk of regressions. A comprehensive test suite is as usual a good idea, and it will generally highly improve your ability to do automatic updates.
One practical and reasonable target for automatic patching is operating systems and frameworks. For example, if you produce an asp.net MVC application you can leverage Microsoft’s reasonably trustable base images and automatically patch the .net runtime when a base image arrives (which is almost immediately for .net releases and frequent for the base OS). The same goes for many other frameworks and container types. For libraries, it is less likely that such a trustable upgrade path exists.
Usefulness Against the Investigated Threats:
| 🟩 | Known Vulnerabilities The system patches itself as fast as possible |
| 🟩 | Semi-Known Vulnerabilities Assuming we receive more fixes than new semi-known vulnerabilities from the patches. Your mileage may vary and depends on the release process of the publisher. |
| 🟨 | Known Vulnerability Class Can go either way, but is unlikely to help us. Newer code is slightly more likely to use better practices |
| 🟥 | Zero-Day Can go either way, but is very unlikely to help us |
| 🟥 | Malicious Publisher Actively bad since we can no longer review the potentially malicious changes |
| 🟥 | Supply Chain Attack Actively bad since we can no longer review the potentially malicious changes |
Mitigation 5: Automatic Pull Requests
Since we want to use recent versions of most components and CVEs for popular components are a common hassle to manage, we want to reduce the amount of manual work needed to patch. Still, as we noticed earlier there are many cases where we cannot patch automatically due to stability or trust issues. Even if that is the case, we can cut down the work needed to patch by using patch automation through pull requests.
The most well-known tool for this is probably GitHub’s Dependabot, but some alternatives are for example Renovate and Snyk.
Ideally, the automatic pull requests trigger a comprehensive test suite to make sure that the update is likely to not break the application. After that, a person reviews the change and either approves or denies the patch.
Usefulness Against the Investigated Threats:
| 🟩 | Known Vulnerabilities If pull requests are applied in a timely manner |
| 🟩 | Semi-Known Vulnerabilities Depending on the quality of the vulnerability feed |
| 🟨 | Known Vulnerability Class Can go either way, but is unlikely to help us. Newer code is slightly more likely to use better practices |
| 🟥 | Zero-Day Can go either way, but is very unlikely to help us |
| 🟥 | Malicious Publisher Can be actively bad since we might apply patches before the information is known |
| 🟥 | Supply Chain Attack Can be actively bad since we might apply patches before the information is known |
Mitigation 6: Quarantine
Several of the previously mentioned tools for automatic pull requests (PR) can wait a while before triggering the PR, instead of doing it immediately as a new version arrives. In case the patch has stability issues or includes new vulnerabilities, it is sometimes welcome to not always apply the latest version. It could be that you want to wait a while to see if other users notice problems with the release before applying it. This is of course only relevant if the patch is not security-critical, or we might end up being exposed to a vulnerability longer than we want to.
But setting up quarantine/wait time for non-security updates can be a reasonable choice for certain dependencies, and it will reduce the workload needed to verify and apply the patches while staying reasonably up to date.
Usefulness Against the Investigated Threats:
| 🟥 | Known Vulnerabilities Actively bad, since we are exposed for a longer time |
| 🟥 | Semi-Known Vulnerabilities Actively bad, since we are exposed for a longer time |
| 🟥 | Known Vulnerability Class Can go either way, but is unlikely to help us |
| 🟥 | Zero-Day Can go either way, but is unlikely to help us |
| 🟩 | Malicious Publisher Yes, if someone notices the malware prior to our patching |
| 🟩 | Supply Chain Attack Yes, if someone notices the malware prior to our patching |
Mitigation 7: Isolation
This is, without doubt, one of our best mitigations, but also the least specific. The purpose of this mitigation class is to reduce the effects of a vulnerability or malware in the component. By not having access to sensitive assets, we reduce the effects of the security event (reduced “blast radius”). However, achieving this is not as simple.
Service Separation and Least Privilege
Splitting services and databases into multiple instances and reducing the access that such instances have can effectively reduce the risk of many third-party component events. Typically, services are split at purpose/domain boundaries, but it is often the case that this coincides with useful security boundaries. For example, if the application processes uploaded files using a complex library, we can look at splitting that logic up into a separate service or serverless function. In case the attacker gains code execution in the processing library, we can limit the effects and perhaps even make the instances temporary to prevent them from accessing other users’ uploaded files.
Sandboxing
Even if a service is not split into many, there could be sandboxing possibilities available to reduce the permissions for certain parts of the application.
But for us to be able to do this we must most often be ready to encapsulate the dependency using some application-specific layer rather than sprinkle the direct usage of the dependency throughout the application. This can have additional positive security effects such as defining and limiting the input types and values that can be passed to the component, but it also comes with an implementation cost. Most often it is more realistic to do for libraries than for frameworks.
Usefulness Against the Investigated Threats:
| 🟩 | Known Vulnerabilities Can potentially reduce the harm from any vulnerability |
| 🟩 | Semi-Known Vulnerabilities Can potentially reduce the harm from any vulnerability |
| 🟩 | Known Vulnerability Class Can potentially reduce the harm from any vulnerability |
| 🟩 | Zero-Day Can potentially reduce the harm from any vulnerability |
| 🟩 | Malicious Publisher Can potentially reduce the harm from any vulnerability |
| 🟩 | Supply Chain Attack Can potentially reduce the harm from any vulnerability |
Mitigation 8: Vendoring
With vendoring, you add the source code of the dependency to your source code repository and typically use that source code to build the binary/package yourself. This would then be done instead of downloading prebuilt packages from a remote package repository or cache. It is traditionally done to guarantee that the package is available or to be able to modify the component, but it also makes it possible to analyze and verify what goes into the dependency without reverse-engineering the output.
Third-party code is most often run with the same privileges as your own code (unless isolated), we often need to trust the quality of the third-party code at the same level as our own or higher. While it might be the case that the quality of certain popular third-party components is higher than that of the average CRUD application, it is not always the case. And regardless, we might want to run our security tooling or even review the third-party code before including it in our application. Since reviewing the component in detail is most likely prohibitively expensive, that is most often reserved for the most security-critical applications (and the largest budgets).
Usefulness Against the Investigated Threats:
| 🟥 | Known Vulnerabilities Does not increase your ability to apply patches |
| 🟥 | Semi-Known Vulnerabilities Does not increase your ability to apply patches |
| 🟨 | Known Vulnerability Class Increases your knowledge and ability to analyze the dependency |
| 🟨 | Zero-Day Increases your knowledge and ability to analyze the dependency |
| 🟨 | Malicious Publisher Could provide value, but do not assume that you can identify the malicious code |
| 🟨 | Supply Chain Attack Could provide value, but do not assume that you can identify the malicious code |
Mapping Threats and Mitigations
Let us map the threats to mitigations and see if the mitigation is at least partly useful against the threat. The mitigations will to a large extent be the same for several threats, but some specific mitigations are needed for each threat. This is of course not an entirely objective analysis and depends on the situation, but let us try to do it in a general fashion:
| Known Vulns | Semi-Known Vulns | Known Vuln Class | Zero-Day Vuln | Malicious Publisher | Supply Chain Attack | |
| Software Composition Analysis (SCA) | 🟩 YES | 🟩 YES | 🟨 YES, if you investigate technologies used |
🟥 NO | 🟨 YES, if you investigate publishers |
🟨 YES, if you investigate publishers |
| Alerting on Vulns | 🟩 YES | 🟩 YES | 🟨 YES, if you investigate technologies used |
🟥 NO | 🟨 YES, if the tool alerts on suspicions |
🟨 YES, if the tool alerts on suspicions |
| Removing Dependencies | 🟩 YES | 🟩 YES | 🟩 YES | 🟩 YES | 🟩 YES | 🟩 YES |
| Automatic Patching | 🟩 YES | 🟩 YES | 🟨 YES, Newer code is slightly more likely to use better practices |
🟥 NO | 🟥 NO, probably increases risk |
🟥 NO, probably increases risk |
| Automatic Pull Requests | 🟩 YES | 🟩 YES | 🟨 YES, Newer code is slightly more likely to use better practices |
🟥 NO | 🟥 NO, probably increases risk |
🟥 NO, probably increases risk |
| Quarantine | 🟥 NO, you are exposed for a longer time |
🟥 NO, you are exposed for a longer time |
🟥 NO | 🟥 NO | 🟩 YES | 🟩 YES |
| Isolation | 🟩 YES | 🟩 YES | 🟩 YES | 🟩 YES | 🟩 YES | 🟩 YES |
| Vendoring | 🟥 NO | 🟥 NO | 🟨 YES, increases ability to analyze the dependency |
🟨 YES, increases ability to analyze the dependency |
🟨 YES, increases ability to analyze the dependency |
🟨 YES, increases ability to analyze the dependency |
So, it seems that the effectiveness of mitigations varies between the threat categories. Removing dependencies/complexity and isolating the use of the dependency almost always has positive effects, but it is of course generally neither realistic nor cost effective. You should do software composition analysis and probably have alerting, but it will not help you much with 0days.
SCA plus alerting is typically packaged in most SCA products on the market, and even though it will not help for the more sophisticated attacks, it will help for the large volume of relevant attacks.
Choosing a Strategy
Now we know how to reason about third party dependencies, what some typical threats are and what some useful mitigations are. Let us try to pick a good set of mitigations that fit our application.
To make things simpler we have combined mitigations into three different packages:
- THE MODERN BASICS – Average risk appetite – Standard mitigations that a security conscious modern project should have.
- STAYING AHEAD – Low risk appetite – A more proactive approach based on patching trusted components early. Requires trusted frameworks and comprehensive test suites.
- NOT TAKING CHANCES – Very low risk appetite – Doing more of everything and assuming an incident is likely. Reduce the potential damage and set the same (high) requirements for third party code as you do for your own.
Putting this together into one infographic we could end up with a staircase like this:
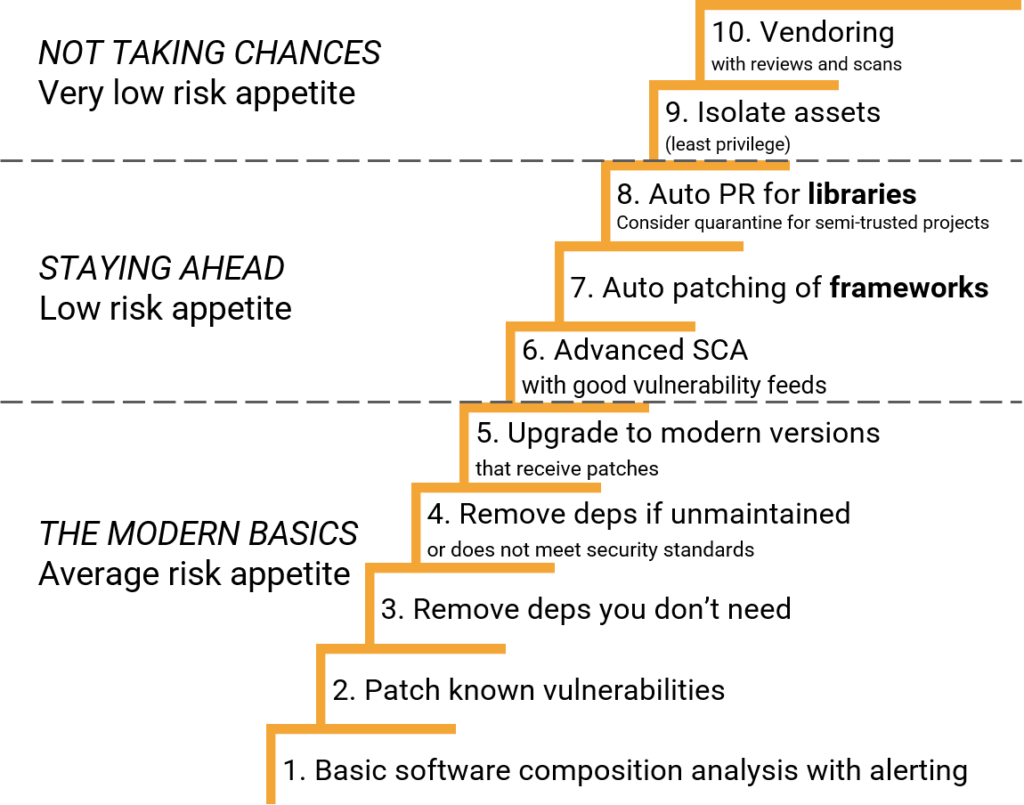
This prioritization is of course highly opinionated and will not match all relevant threat models or development processes. We feel it maps well to the reality of threats and security budgets for most companies, but your milage may vary.
Additional Threats and Mitigations to Consider
Some honorable mentions that we did not cover in detail in this blog post:
An attacker publishes a malicious component with a name similar to the one you want to use (“typo-squatting”).
Setting requirements on included packages and doing additional reviews will alleviate this. One can also use a filtered package repository where dependencies must be in a reviewed allow list.
An attacker publishes a malicious component with the same name as an internal component, fooling the package manager to choose that one instead of the internal one (“dependency confusion”)
Mitigations depends on the package manager and configuration, but in general we want to make sure to prioritize our internal package list (both client side and at the repository).
An attacker breaches a package repository to serve malicious code with the components.
Hashes and/or signatures of packages are mitigations beyond general protections of the repository. Verifying signatures is rarely practically possible in most package managers due to lack of signatures or tooling. More often it is possible to verify hashes of the data, but the hashes will naturally change for each new version, so a secure source of hashes will still be needed for higher trust levels.
A vulnerable version is selected instead of the newer patched version (at a build server or client) due to packages not having strict version definitions
The typical mitigation would be to lock version numbers of all things that should not be auto patched, and make sure caching cannot cause an older version to be selected at for example a build server.
Container/docker layer caching leads to packages not being updated as expected, rendering a vulnerable version.
Layer caching is immensely useful when building containers since we do not need to rerun each step each time a Dockerfile or input file is changed. But it also means that if we rely on caching when selecting a base image or running an upgrade script, we might end up using an old version when we did not want to. Mitigations depend on the build structure and environment, but for example the flags –pull and/or –no-cache can often be used to verify that the latest version is used when building the image.
Runtime Application Self-Protection (RASP)
A general mitigation technique that is sometimes said to at least partly solve dependency risk (along with other problems) is Runtime application self-protection (RASP). RASP tooling runs alongside/inside your application and tries to monitor or counter vulnerabilities/exploitation. Using for example rule engines or machine learning, they aim to identify dangerous or unexpected behavior in the running application and thus be able to stop an attack even for 0days.
If this sounds futuristic or too good to be true, it is probably because it still is to some extent. A RASP can be a useful addition for many systems; ranging from secure applications that want additional protections to lower quality systems that need a band-aid to reduce risk. Thus, they fill a similar slot as web application firewalls (WAF), except with a better potential for identifying and stopping malicious behavior. Like WAFs, they will not be able to mitigate all types of threats and should only be used as an addition to application security practices rather than as a replacement.
Future Developments
Many of the useful protections for third-party components are the same as for your own code. Beyond existing tools that can alert on known vulnerabilities we need to focus on risk reduction.
The world of software development has not embraced the ideas of strict authorization and isolation. This is understandable, since such work is generally not rewarded or visible. It becomes visible only when an attack happens that exposes a lack of controls.
Software projects have tight schedules and developers are often stressed. For us to solve these problems better the solutions must be simple to use and non-intrusive. We must still be able to use plenty of third-party components. Otherwise we must dramatically scale back the expected functionality and increase the budgets and staffing requirements for most software projects.
Luckily there are many individuals and organizations working on these problems. As the attacks increase, let us also hope that our ability to mitigate them increases as well.
Sandboxing
The Java sandbox (security manager) has a target on its back, but the idea of isolating parts of software systems is alive and well. There is for example work being done in academia regarding isolation within an application, such as Enclosure.
Service Separation and Least Privilege
The movement towards microservices and domain-specific data repositories also provides a possibility to isolate assets and component usage into specific services with little access to other services and datastores. In many microservice implementations that is not actually true since the service authorization between most microservices and databases is often non-existent or lacking, but the potential is there.
More complex orchestration frameworks such as Kubernetes provide most building blocks and interfaces to isolate services decently. The general interest in all things that can be labeled Zero trust could benefit third-party component risk, and using advanced authorization/policy frameworks such as Open Policy Agent or just custom policies in frameworks such as Istio could provide basis for harm reduction and isolation for many threats both from components and vulnerabilities in the business code.
Runtime Protections
As mentioned previously, RASP is an emerging field, and if or how such technology will be used broadly in the future is hard to tell, but they can potentially serve as a dynamic sandbox/isolation and be able to fend off certain attacks that for example a web application firewall (WAF) never can. Such tooling is currently expensive and mainly geared towards larger enterprises but could become more available and common in the future.
Industry Collaborations
The Linux Foundation, Open Source Security Foundation (OSSF), OWASP and many more have exciting, tools, collaboration and general efforts to identify and manage problems with using open source components. There are challenges to overcome, but large efforts are being taken to make sure the eco-system is trustable and transparent. It is in everyone’s interest, perhaps mostly so for enterprises that have come to depend on open source components.
Conclusion of Part 2
One can imagine many threats stemming from third-party component usage, but it is also often relatively easy to decrease your risk exposure by making smart choices in mitigations. Focusing on using secure and trustable base frameworks and libraries and leveraging auto-patching and/or automatic pull requests can remove much vulnerability exposure as well as cut down triage work that otherwise comes with caring about what goes into the software.
It may sound too basic or obvious, but just looking at what goes into your software and making sure you have patched and are using recent versions that are likely to receive patches will put you in a pretty good position in case something happens. Beyond that, exciting industry measures and collaborations will hopefully make it easier to manage third-party component risk in the future.
Are you interested in helping companies build secure software and work on cool technical problems? We are always looking for new colleagues. Make sure to check out our career page. If there is no specific position listed, use an open application and connect with us!
Stay ahead with cyber insights
Newsletter
Stay ahead in cybersecurity! Sign up for Truesec’s newsletter to receive the latest insights, expert tips, and industry news directly to your inbox. Join our community of professionals and stay informed about emerging threats, best practices, and exclusive updates from Truesec.
Your current browser privacy settings may be preventing this form from loading properly. To continue, please allow cookies/tracking for this site or temporarily disable strict privacy protection, then refresh the page.
If you’re still experiencing issues, please contact us at hello@truesec.com


