

Part One
Secure Your Software Supply Chain – Trusting Third Parties
In this first post we discuss publishers, trust, and measurements. In part two the focus is on technical threats and mitigations surrounding third-party components.
- Insight

In an earlier blog post, we looked at how to avoid becoming a vector for a software supply chain attack. In this two-part article, we will mainly look at how you as a consumer of third-party and/or open-source software can identify vendors to trust and mitigate the different relevant threats. Let’s take a pragmatic approach and look for mitigations that help us improve security while staying productive. In this first post, we discuss publishers, trust, and measurements. In part two the focus is on technical threats and mitigations surrounding third-party components.
The Software Supply Chain Problem
Managing the different classes of threats from dependencies is complex, and there is no single tool to solve all problems. An oft-cited example comes from GitHub’s “The 2020 State of the Octoverse”: The median number of transitive (indirect) dependencies for a JavaScript project on GitHub is 683. That number might include duplicates or common publishers, and the JavaScript (npm) ecosystem is extreme in this regard. Regardless, we most often rely on hundreds of different suppliers that we know very little about. How do we handle vulnerabilities or supply chain risk in such a scenario?
Even if we assume that the publishers are not malicious, it means large amounts of code that may expand the attack surface of the system.
The Solution: Risk Reduction
For most organizations, it is possible to reduce the risk through awareness, sound policies, and automation. By understanding what the potential threats are and what measures we can take, it is possible to improve the security posture and reduce the risk of a critical security breach happening. We will focus on how you can improve your security posture today, but also glance at what the future might hold.
In the first part, we will explore vendor trust and the need to be aware of what code goes into your application. In the second part, we will look at potential threats from using third-party dependencies and potential mitigations to those threats.
As a simple call to action for developers, we present three general levels of mitigations and countermeasures. These are adapted to project budget and risk appetite. In an ideal world, such measures are meticulously selected per project, but in reality, we must often rely on best practices and common mitigations.
When Using Dependencies is Good for Security
Tool vendors and cybersecurity companies tend to look at third-party dependencies as a risk. We are not innocent of this, which this blog post is a testament to. It is important to not forget the massive positive effect that third-party code and open source have on the security of modern software projects.
Secure Defaults
Modern frameworks such as web frameworks come with mostly secure defaults. Using a frontend JavaScript framework these days will often mostly protect the user from cross-site scripting. Using a backend framework will most often add or make accessible reasonable HTTP headers, flags, and behaviors to avoid the most common attacks.
High-Quality Security Libraries
Developers can leverage high-quality and vetted security libraries for encryption, deployment, and similar security-sensitive operations. When Truesec reviews customer code, we might find misuse of cryptographic libraries. Fully homegrown cryptosystems that are completely broken are rare to see. This has changed in the last few years as the availability of decent or good libraries and guides for encryption have become more available.
DevSecOps Tooling
A modern and mature software development lifecycle utilizes learnings from the DevSecOps movement. Adding automation in the form of linting, static code analysis, dynamic application security testing, etc. can improve the security of both your process and applications. There are many tools available both for free and at a cost that can help improve the security of your applications.
What Is the Worst That Could Happen?
While we like to think about the worst possible outcomes from threats, the more important question to improve security is: What could reasonably happen? And what do threat intelligence and history tells us about ways that systems are attacked?
Threat Actor Behavior
It used to be that we could wait quite a while before patching vulnerabilities in IT systems or applications. Testing for compatibility and not disturbing availability made us reluctant to patch systems. When it comes to vulnerability management, that was not a great policy then, and it is certainly not a great policy now. The time window from the publication of a critical vulnerability to active exploitation by threat actors is shrinking every day.
Threat actors no longer need to choose a system and figure out an exploit. It is easier to have the systems mapped and attempt attacks on many potential victims. Selecting the targets can be done after the initial breach has already happened. Critical exploitable vulnerabilities need to be patched immediately, and we need to make sure that we have the capability to patch or mitigate if a vulnerability becomes known. We cannot spend time figuring out if we use the component in question and if the patching should be delayed to some patch window in a weeks’ time. Systems must be built to be able to be patched and we must know when a patch is needed.
Potential Sources of Vulnerable Components
If we look at a common software development process, it could look something like this:
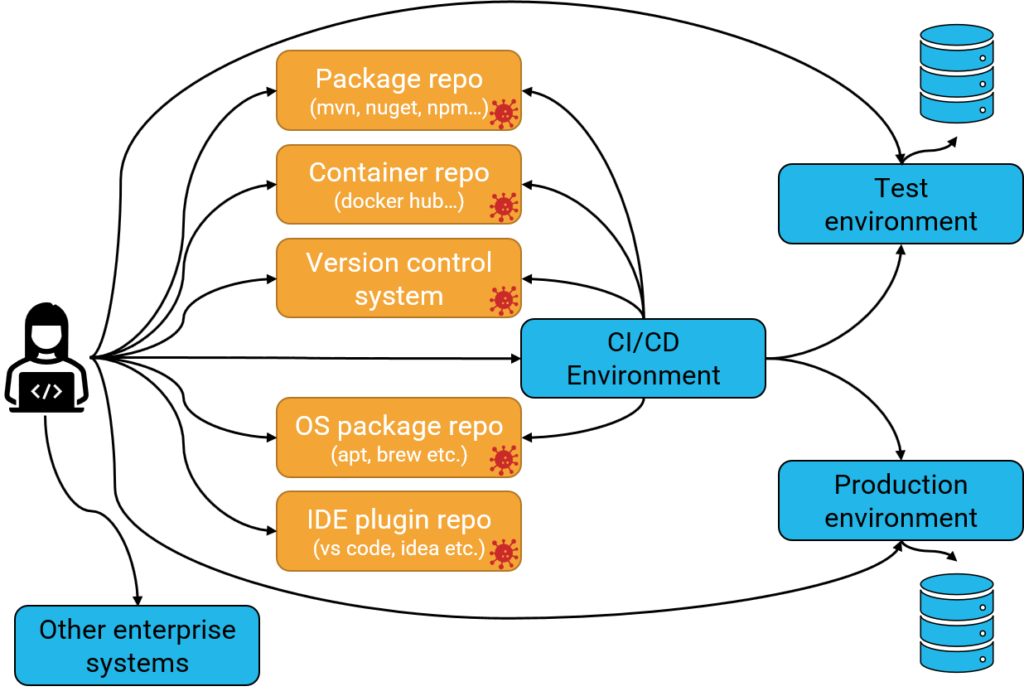
We often download third-party components from several different sources:
- Package repositories such as nuget, npm, or maven.
- Container repositories such as Docker hub.
- Third-party code embedded into the source code repository.
- Operating system packages used to develop and build our code.
- Developer tools and plugins that help us build the software. This is an increasing area due to the popularity of Visual Studio Code and its plugin repository. Such marketplaces make the lines between official components and external components fuzzy.
The systems are connected to each other. In real life, there are many more systems and arrows indicating interactions.
Effects of Vulnerable or Malicious Components
If vulnerable or malicious code is downloaded and run on either the developer’s computer or the CI/CD environment we might end up with something like this:
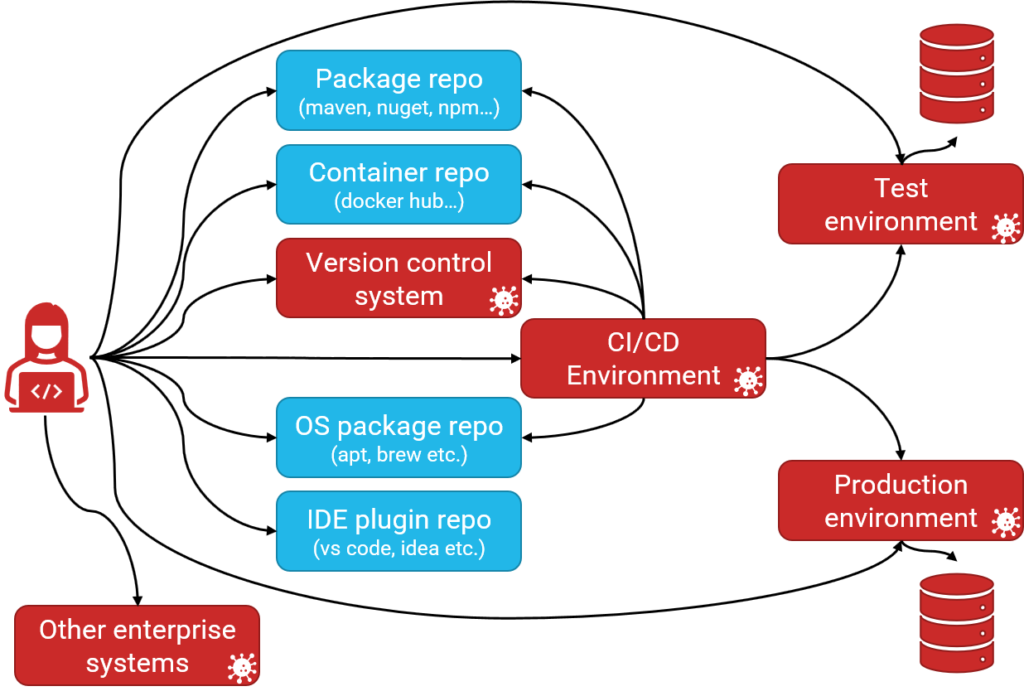
The vulnerable or potentially malicious code could have effects not just by exposing the production environment. It could also expose vulnerabilities in the CI/CD environment, on the developer’s computer, or in other enterprise systems. Potentially it could even be malicious code and actively attempt or spread through the connected systems.
Becoming Part of a Supply Chain Attack
Another general case is where the developer computer and/or build systems are used to provide software to other users. The produced software could contain vulnerabilities from third-party components, but there is also the risk of a malicious publisher adding malware that attacks the end user’s systems (a supply chain attack). Protecting from similar scenarios is covered in more detail in our previous blog post: Avoiding supply-chain attacks similar to SolarWinds Orion’s (SUNBURST).

Trusting Publishers
Since we run the third-party code together with our code and our sensitive assets, we must really trust the publishers of the third-party software quite a bit. At the same time, software teams typically do not know who the third-party publishers are, nor how they work with security. In many cases, the software used is open source from publishers generously donating their time.
To make a terrible analogy: We cannot reasonably expect a free lunch and complain if the dish is a bit too salty for our taste, but we might want to avoid eating obscure five-year-old food from the street. We might also want to verify that the host does not actively attempt to poison us. Some say the best food is served from obscure street vendors, and that might be true, but perhaps avoid those on your wedding day.
Will the Many Eyes Protect Us?
Most often a developer will find confidence in the fact that a component is used by other well-known projects. We hope that those projects have vetted and assessed the component at hand. And while that is a logical starting point, it will likely limit their ability to leverage interesting new components. Most often there are no guarantees and no stated information about if or how those well-known projects in fact vet their dependencies. We do not want to end up in a situation where more and more projects start relying on components due to other projects doing so unless we can be reasonably certain that someone has verified the project.
To some extent we need to decide if we believe that the situation relates to Linus’s Law or to The Emperor’s New Clothes.
Trying to Outsource the Problem
Not having a support contact has traditionally made many business stakeholders uneasy and reluctant to rely on open source. However, in the last few years, that has changed even among most conservative entities; the productivity gains from open-source components are simply too tempting to ignore. Organizations are now, to a higher extent, willing to build their software on unknown components. Beyond a productivity increase, it also keeps employees happy in a competitive labor market.
One classic method to reduce the risk and alleviate managerial stress is to use components through trusted providers. You might sign commercial agreements promising security feeds and availability of functionality (which is a large part of RedHat’s business model). Another method is to purchase tooling promising to solve the problem. Both methods can be useful if you are aware that there can be delays and limitations in what you can use through the commercial “proxy”, and that the expensive tooling will not solve all the issues for you. And those support contracts certainly do not guarantee that there are no security vulnerabilities.
Properties of Third-Party Components
Even if we have never actually actively investigated our dependencies, it is likely that we want our dependencies to match a few properties to reduce risk. We would ask ourselves questions such as:
| ⬜ | Is the project license acceptable? | ⬜ | Does the project have a trustable sponsor/owner? |
| ⬜ | Is it a known/established project? | ⬜ | Is the project trusted by projects you trust? |
| ⬜ | Is the project actively maintained? | ⬜ | Are there any dependencies on other projects (transitive)? |
| ⬜ | Are there several active developers? | ⬜ | Is there a documented security policy? |
| ⬜ | Are the main developers known from other projects? | ⬜ | Is there a documented threat model? |
| ⬜ | Is the project large/complex? | ⬜ | Does the project have a good history of managing vulnerabilities? |
| ⬜ | Is there a structured roadmap? | ⬜ | Are the releases signed? |
| ⬜ | Are there important unfixed bugs and vulnerabilities? | ⬜ | Are there badges/verifications regarding supply chain security available? |
Exactly which properties are important depends on the organization, project, and risk appetite. We can, however, say that a system that has sensitive assets and uses unverified or non-trusted publishers is likely to be exposed to more risk than what the organization would like to acknowledge. Most of the time, projects end up informally verifying the direct dependencies and then hoping that the publisher does the same for the transitive dependencies. Just don’t count on that being true.
Mapping Trust to Assets
If we try to map publisher trust to asset sensitivity, we could end up with something like this:
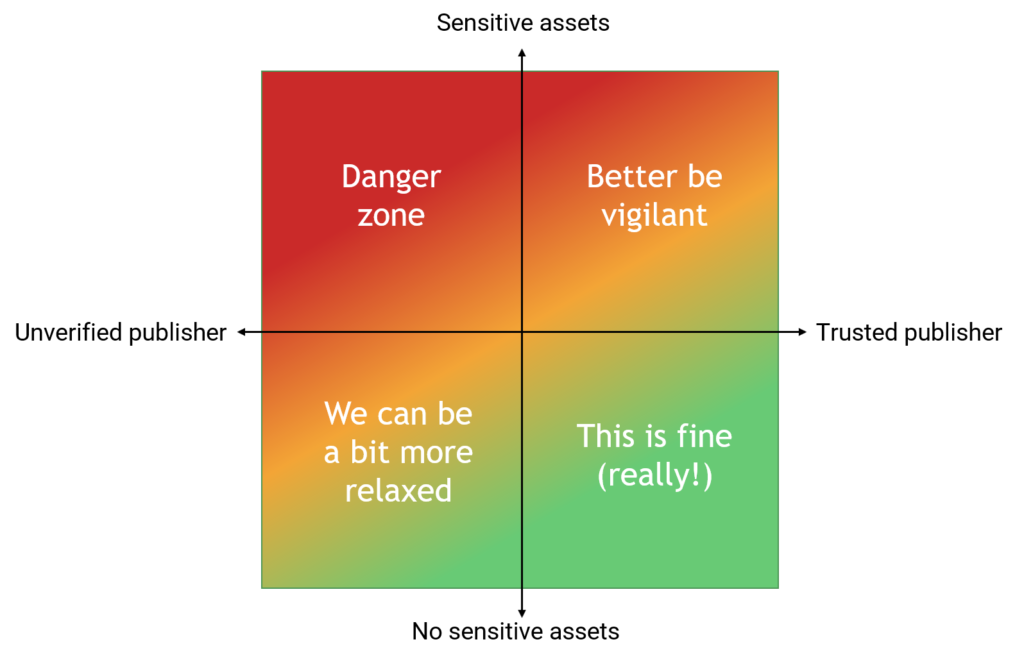
The point of the figure above is to illustrate that we likely must accept risk from third-party dependencies. That risk must be calculated based on what the negative effects of a security incident stemming from the dependencies might be in relation to the probability of the thing actually happening.
As trust increases, we expect that the probability of a bad event decreases. We can thus accept a worse worst-case scenario coming from a supplier we trust than from one we do not trust. But we must first establish that trust level.
Getting Data on Trust
Doing due diligence on an organization or a background check of a publisher is time-consuming. How well you must know your suppliers will depend greatly on your threat model. If we are using open source components from the Internet it is likely difficult to investigate the individual trust in the developers. There is however sometimes a potential to review build processes and review processes. This could give a greater insight into how the component is built and sourced.
Some commercial Software Composition Analysis (SCA) tools attempt to calculate properties and can help with identifying licensing issues, abandoned projects, etc.
Scorecards and SBOMs
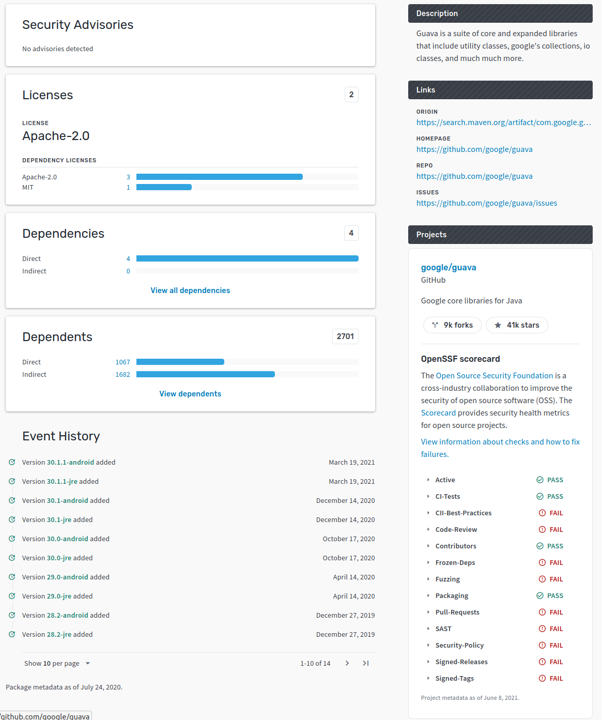
The Open Source Security Foundation’s “Scorecard” project aims to analyze and provide insights into how a component is built and maintained. Similarly SLSA: Supply-chain Levels for Software Artifacts (intro blog post, repo) is a work-in-progress framework for identifying and verifying trust levels. If SLSA were widely used is could become possible for the consuming software toolchain to verify certain properties of the used dependency.
To get more information on the contents of a component, there are standards for Software Bill-of-Materials (SBOMs), such as the Software Package Data Exchange (SPDX). An interesting development is the release of the experimental Open Source Insights project (“deps.dev”). This site provides basic information about known vulnerabilities, licenses, dependencies, and to some extent OSSF scorecards for open source projects in several popular package managers.
Leveraging the Fact That We Do Not Trust All Vendors Equally
In any software project, there will be some vendors that you absolutely must trust, as they are often very difficult or impossible to remove. The programming language runtime will probably not be easily replaced, nor will the web framework you choose to build a web app on. Naturally, these vendors and sources must be highly trustable. If we have focused on making sure these are secure, it also gives us some additional benefits when it comes to automatic patching as we will see later.
Such dependencies typically process data early in the call stack. The runtime or web framework will for example typically process the potentially dangerous data from the client before your custom application code can act on it. Coupled with the fact that common frameworks are easy to fingerprint for attackers and often have simple-to-use exploits makes it so that we have even more reason to make sure we trust the frameworks.
Frameworks vs. Libraries
As a rule, we can use this simplification:
- A framework is typically something that calls your code
- A library is typically something you call from your code

Note that in many cases an application adds parsing libraries or middleware that acts prior to the application logic. By doing so you often remove your ability to validate or protect the third-party code from malicious input and should therefore consider them on par with the framework when it comes to trust.
Without looking at threats, we can conclude that we must be extra vigilant when it comes to frameworks and other code handling potentially malicious input prior to our own logic.
Patching and making sure frameworks are securely configured will be some of the most effective measures to avoid common security issues in modern applications.
Mapping to an Application Security Journey
While managing third-party dependency risk is important, it is only one piece of the puzzle that is secure software development. By measuring and following up on our development practices we can identify areas that need improvement. Such assessment should be simple to perform and should map to actionable items for your backlog if a control is missing. They are not compliance frameworks.
OWASP SAMM
To assess a development process, we can for example choose to use OWASP SAMM. In OWASP SAMM we categorize the project into five business functions with three practices each. These practices have two streams where a project is measured to be on maturity level 1-3. Third-party dependencies mainly fall in the streams Software Dependencies and Patching and updating:
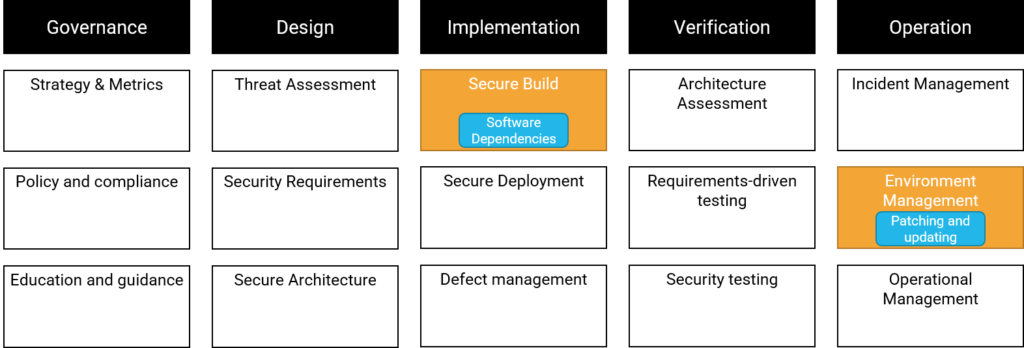
This illustrates that while managing third-party dependencies is important, there are obviously many more aspects of secure development. It is not reasonable to reach the highest security level for all such aspects. We want to reach an acceptable level of risk. That will only be possible if we choose to distribute our security budget reasonably between the different activities. Which threats we choose to focus more on will be dependent on the organization and the threat model.
SLSA
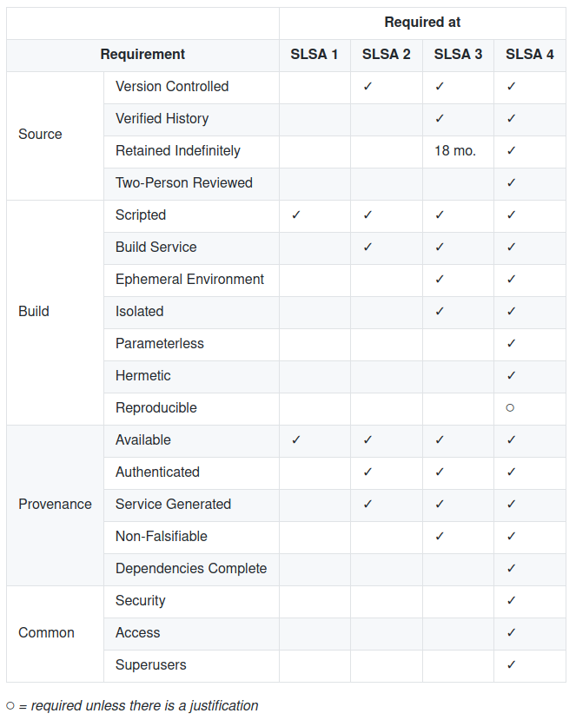
Another interesting and useful maturity/security assessment for usage and production of software is SLSA, which we mentioned previously. SLSA has a much more narrow scope than OWASP SAMM and does not aim to be a full maturity assessment, but is also more detailed in the areas covered.
It currently defines four levels ranging from “no integrity guarantees” to “auditable and non-unilateral”. The highest level means that we can be reasonably certain of the contents of the package and that important changes to the package cannot be performed by one single person without review. While this is mainly aimed at projects that produce components for other software projects, most of the properties are relevant to proprietary custom software as well. SLSA aims to cover many of the threats from using dependencies as well.
Conclusion of Part 1
Managing third-party dependencies/components is an important part of a secure development process. Combining this with the power of freely available open-source components and useful commercial offerings can be hard. We need to know the potential risks involved and take informed choices when it comes to trusting dependencies. Open source and commercial components provide fantastic opportunities in productivity, developer happiness, and even security. But we must weigh the risks just as we hopefully do when we are implementing functionality in our applications.
In part two, we will look at how to categorize threats and mitigations a bit more formally. We will also try to identify best practices when it comes to handling third-party components.
Read Part 2: Threats and Mitigations
Go to part two in this article series: Secure Your Software Supply Chain – Threats and Mitigations
Is This Topic Right Up Your Alley?
Are you interested in helping companies build secure software and work on cool technical problems? We are always looking for new colleagues. Make sure to check out our career page. If there is no specific position listed, use an open application to connect with us!
Stay ahead with cyber insights
Newsletter
Stay ahead in cybersecurity! Sign up for Truesec’s newsletter to receive the latest insights, expert tips, and industry news directly to your inbox. Join our community of professionals and stay informed about emerging threats, best practices, and exclusive updates from Truesec.
Latest AI Insights

AI Agent OpenClaw Poses Serious Cybersecurity Risks

Chrome Extension Steal ChatGPT and DeepSeek Conversations
